


In today’s digital landscape, the reliability of applications and services is paramount. As organizations strive to provide seamless user experiences, the role of Site Reliability Engineering (SRE) becomes increasingly crucial. The SRE Playbook provides a comprehensive guide to implementing effective reliability practices, ensuring your services are resilient, scalable, and performant. This article delves into the key principles of SRE, offering practical insights and strategies to help your team achieve operational excellence.
What is Site Reliability Engineering (SRE)?
Site Reliability Engineering (SRE) is a discipline that combines key aspects of software engineering and applies them to enterprise infrastructure and operations problems. The main goals of SRE are to create scalable and highly reliable software systems. Initially developed by Google, SRE has since been adopted by numerous organizations worldwide, thanks to its proven effectiveness in enhancing service reliability.
Key Principles of SRE
1. Embracing Risk
One of the foundational principles of SRE is the acceptance and management of risk. Absolute reliability is neither possible nor cost-effective. Instead, SRE aims to find the right balance between risk and reliability. This involves defining Service Level Objectives (SLOs) that specify the acceptable service performance and availability level.
2. Service Level Objectives (SLOs) and Service Level Agreements (SLAs)
SLOs are the backbone of SRE, providing measurable targets for system performance. An SLO might state that a service should have 99.9% uptime over a given period. SLAs, on the other hand, are formal agreements with customers based on these SLOs. By setting clear SLOs and SLAs, organizations can make informed decisions about what works to prioritize and to which project resources need to be allocated.
Implementing SRE Practices
1. Monitoring and Observability
Effective monitoring and observability are critical to understanding the health of your systems. Monitoring involves tracking key performance indicators (KPIs) such as latency, error rates, and system throughput. Observability goes a step further, providing insights into the internal state of systems based on their external outputs.
Key Metrics to Monitor:
- Latency: The time taken to process a request.
- Error Rates: The frequency of failed requests.
- Throughput: The number of requests processed in a given time.
- Resource Utilization: CPU, memory, and disk usage.
2. Incident Management
Despite the best preventive measures, incidents are inevitable. A robust incident management process is essential for minimizing the impact of outages and ensuring quick recovery. This involves:
- Incident Detection: Using monitoring tools to quickly identify issues.
- Incident Response: A well-defined process for addressing incidents, including roles, responsibilities, and communication protocols.
- Post-Incident Reviews: Conducting thorough reviews to identify root causes and implement preventive measures.
3. Automation and Tooling
Automation is a key enabler of SRE practices, reducing manual toil and increasing efficiency. By automating repetitive tasks such as deployments, scaling, and monitoring, teams can focus on more strategic work. Some popular tools used in SRE include:
- Prometheus: For monitoring and alerting.
- Grafana: For data visualization.
- Kubernetes: For container orchestration.
- Terraform: For infrastructure as code.
The Role of Culture in SRE
The success of SRE implementation is not just about tools and processes; it’s also about fostering a culture of reliability. This involves:
- Blameless Culture: Encouraging open discussion of failures without fear of blame or punishment.
- Collaboration: Promoting close collaboration between development and operations teams.
- Continuous Improvement: Constantly seeking ways to enhance reliability and performance.
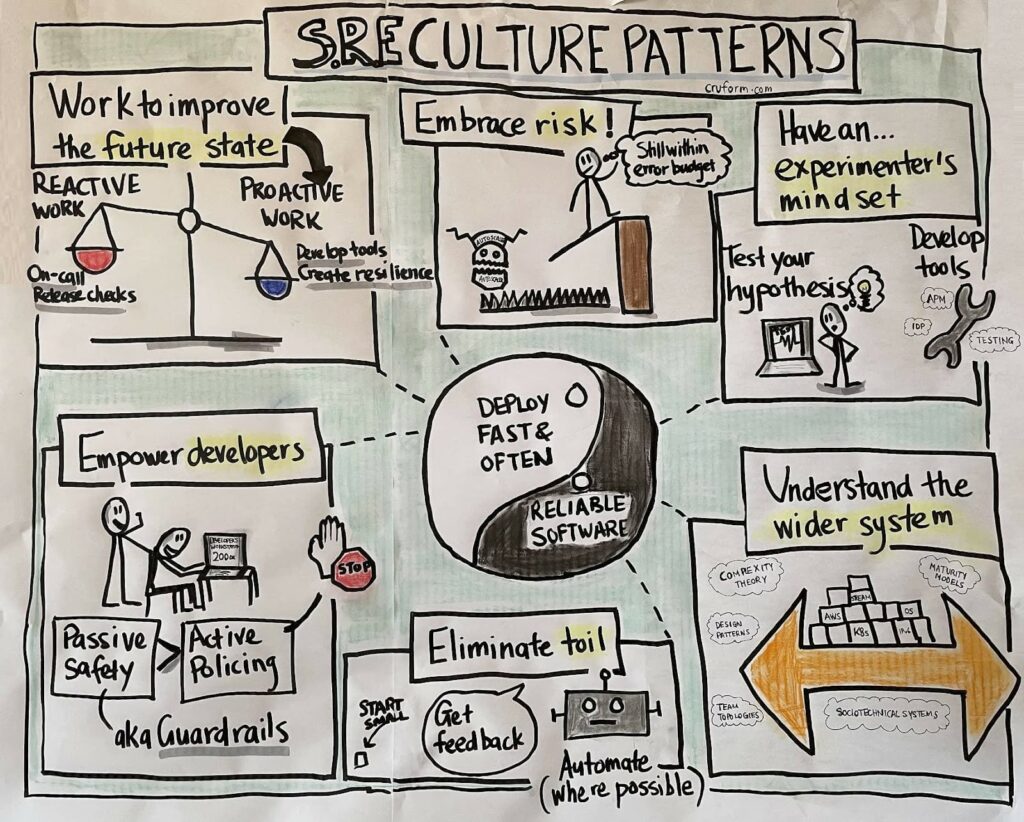
Case Studies: Successful SRE Implementations
1. Google
As the pioneer of SRE, Google’s approach to reliability has set the standard for the industry. Google’s SRE teams focus on automating operations, defining clear SLOs, and fostering a culture of continuous improvement. This has enabled Google to maintain high levels of service reliability while rapidly deploying new features.
2. Netflix
Netflix employs SRE principles to ensure its streaming service is always available to its global audience. By leveraging chaos engineering, Netflix proactively tests the resilience of its systems to identify and address potential weaknesses before they impact users.
Challenges in SRE Implementation
Implementing SRE is not without its challenges. Some common obstacles include:
- Cultural Resistance: Shifting to an SRE model requires significant cultural change, which can be met with resistance from teams accustomed to traditional operations.
- Skill Gaps: SRE requires a unique blend of software engineering and operations skills, which may not be readily available in existing teams.
- Tool Integration: Integrating various monitoring, automation, and incident management tools can be complex and time-consuming.
Overcoming SRE Challenges
1. Education and Training
Investing in education and training is crucial to overcome skill gaps and cultural resistance. This can include formal SRE Foundation training and SRE Practitioner training programs, workshops, and hands-on practice with SRE tools and techniques.
2. Incremental Adoption
Instead of a wholesale shift to SRE, consider adopting its practices incrementally. Start with key services and gradually expand as the organization gains confidence and experience.
3. Leveraging Cloud Services
Cloud providers offer a wide range of services that can simplify SRE implementation. For example, managed Kubernetes services, monitoring solutions, and automated scaling can reduce the operational burden on teams.
Future Trends in SRE
As technology evolves, so too will SRE practices. Some emerging trends include:
- AI and Machine Learning: Leveraging AI and ML to enhance monitoring, incident detection, and root cause analysis.
- Edge Computing: Addressing the unique reliability challenges of edge computing environments.
- Serverless Architectures: Adapting SRE practices to the dynamic nature of serverless applications.
Conclusion
The SRE Playbook provides a robust framework for achieving high reliability in modern software systems. By embracing risk, defining clear SLOs, implementing effective monitoring and incident management, and fostering a culture of collaboration and continuous improvement, businesses can ensure their services meet the demands of today’s digital economy. As SRE practices continue to evolve, staying informed about critical emerging trends and technologies will be key to maintaining a competitive edge in reliability and performance.
References
- Google SRE Book
- Prometheus
- Grafana
- Kubernetes
- Netflix Technology Blog